Testing with managed effects
We have seen how to use effects, and we have seen a little bit about the testing, but we should look at that closer.
Crux was expressly designed to support easy, fast, comprehensive testing of your application. Everyone is generally on board with unit tests and TDD when it comes to basic pure logic. But as soon as any I/O or UI gets involved, the dread sets in. We're going to have to set up some fakes, introduce additional traits just to test things, or just bite the bullet and build tests around a fully integrated app and wait for them to run (and probably fail on a race condition sometimes). So most people give up.
Managed effects smooth over that big hump. You pay for it a little bit in how the code is written, but you reap the reward in testing it. This is because the core that uses managed effects is pure and therefore completely deterministic — all the side effects are pushed to the shell.
It's straightforward to write an exhaustive set of unit tests that give you complete confidence in the correctness of your application code — you can test the behavior of your application independently of platform-specific UI and API calls.
There is no need to mock/stub anything, and there is no need to write integration tests.
Not only are the unit tests easy to write, but they run extremely quickly, and can be run in parallel.
For example, here's a test that drives LocalWeather through a full weather fetch — checking location permission, resolving the location, then handling the weather response. A setup helper advances the state machine through the first two events by resolving each effect with a canned response:
#![allow(unused)] fn main() { /// Drives the state machine from `FetchingLocation` through to `FetchingWeather`, /// resolving location and returning the state + command ready for a weather response. fn drive_to_fetching_weather() -> (LocalWeather, Command<Effect, LocalWeatherEvent>) { let local = LocalWeather::default(); let key = api_key(); let (local, mut cmd) = local .update(LocalWeatherEvent::LocationEnabled(true), &key) .expect_continue() .into_parts(); let event = cmd .resolve_location(|_op| LocationResult::Location(Some(phoenix_location()))) .expect_event(); local.update(event, &key).expect_continue().into_parts() } }
The test itself picks up from FetchingWeather, resolves the HTTP effect, and asserts that the final state is Fetched with the expected data:
#![allow(unused)] fn main() { #[test] fn weather_fetched_stores_data() { let (local, mut cmd) = drive_to_fetching_weather(); assert!(matches!(local, LocalWeather::FetchingWeather(_))); let event = cmd .resolve_http(|_op| { HttpResult::Ok( HttpResponse::ok() .body(phoenix_weather_json().as_bytes()) .build(), ) }) .expect_event(); let (local, _cmd) = local .update(event, &api_key()) .expect_continue() .into_parts(); let LocalWeather::Fetched(loc, ref data) = local else { panic!("Expected Fetched state, got {local:?}"); }; assert_eq!(loc, phoenix_location()); assert_eq!(data.as_ref(), &phoenix_weather_response()); insta::assert_yaml_snapshot!(data.as_ref()); } }
It's a test of a whole interaction with multiple kinds of effects — location services and HTTP — and it runs in a couple of milliseconds, entirely deterministic. The code being tested is LocalWeather::update from chapter 4; managed effects let us verify the whole transaction without executing any of it.
The full suite of 57 tests of the Weather app runs in around 20 milliseconds on a Mac Mini M4 Pro. In practice, it's rare for a test suite of a Crux app to take longer than compiling it (even incrementally). Apps with thousands of tests usually run them in seconds, though compilation takes longer.
cargo nextest run
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.28s
────────────
Starting 57 tests across 1 binary
...
Summary [ 0.020s] 57 tests run: 57 passed, 0 skipped
The test steps
Crux gives us a chainable test API that keeps assertions concise, but you still drive the event → update → effect → resolve cycle yourself. You'll see methods like .expect_only_render() and .resolve_http(|op| ...) on Command throughout this chapter. They come from an EffectTestExt trait the #[effect] macro generates next to your Effect enum when crux_core's testing feature is enabled, and auto-implements for Command<Effect, E> where E is an event.
Let's walk through a simpler test from the Weather app step by step:
#![allow(unused)] fn main() { #[test] fn location_enabled_fetches_location() { let local = LocalWeather::default(); let (local, mut cmd) = local .update(LocalWeatherEvent::LocationEnabled(true), &api_key()) .expect_continue() .into_parts(); assert!(matches!(local, LocalWeather::FetchingLocation)); cmd.expect_only_location_with(|op| { assert_eq!(op, &LocationOperation::GetLocation); }); } }
First, we build a fresh LocalWeather::default(). Its starting state is CheckingPermission.
We then call update with LocationEnabled(true), as if the shell had just reported that location services are available. update returns an Outcome, which we destructure with .expect_continue().into_parts(). We know this event doesn't complete the state machine, so we assert on Continue and get back the updated state plus any command.
We assert the new state is FetchingLocation. Then we call .expect_only_location_with(|op| ...) on the command. That one chained call says "the only effect on this command is a Location effect, and here's a closure to inspect its operation." Inside the closure we check the operation is GetLocation.
That's the whole test. update is a pure function, so there's nothing to set up beyond the initial state and nothing to tear down.
More integrated tests and deterministic simulation testing
We could test the key-value storage in a more integrated fashion too - instead of asserting
on the key value operation, we can provide a very basic implementation of a key value store
to use in tests, using a HashMap as storage for example. Then we could simply forward the
key-value effects to it and make sure the storage is managed correctly. Similarly, we could
build a predictable replica of an API service we need to test against, etc.
While that's all starting to sound a lot like mocking, remember that we're not implementing Redis or building an actual HTTP server. It's all very simple code. And if we do that for all the different effects our app needs and provide a realistic enough implementation to mimic the real things, a very interesting thing happens - we get the entire app stack, with the nitty gritty technical details taken out, running in a unit test.
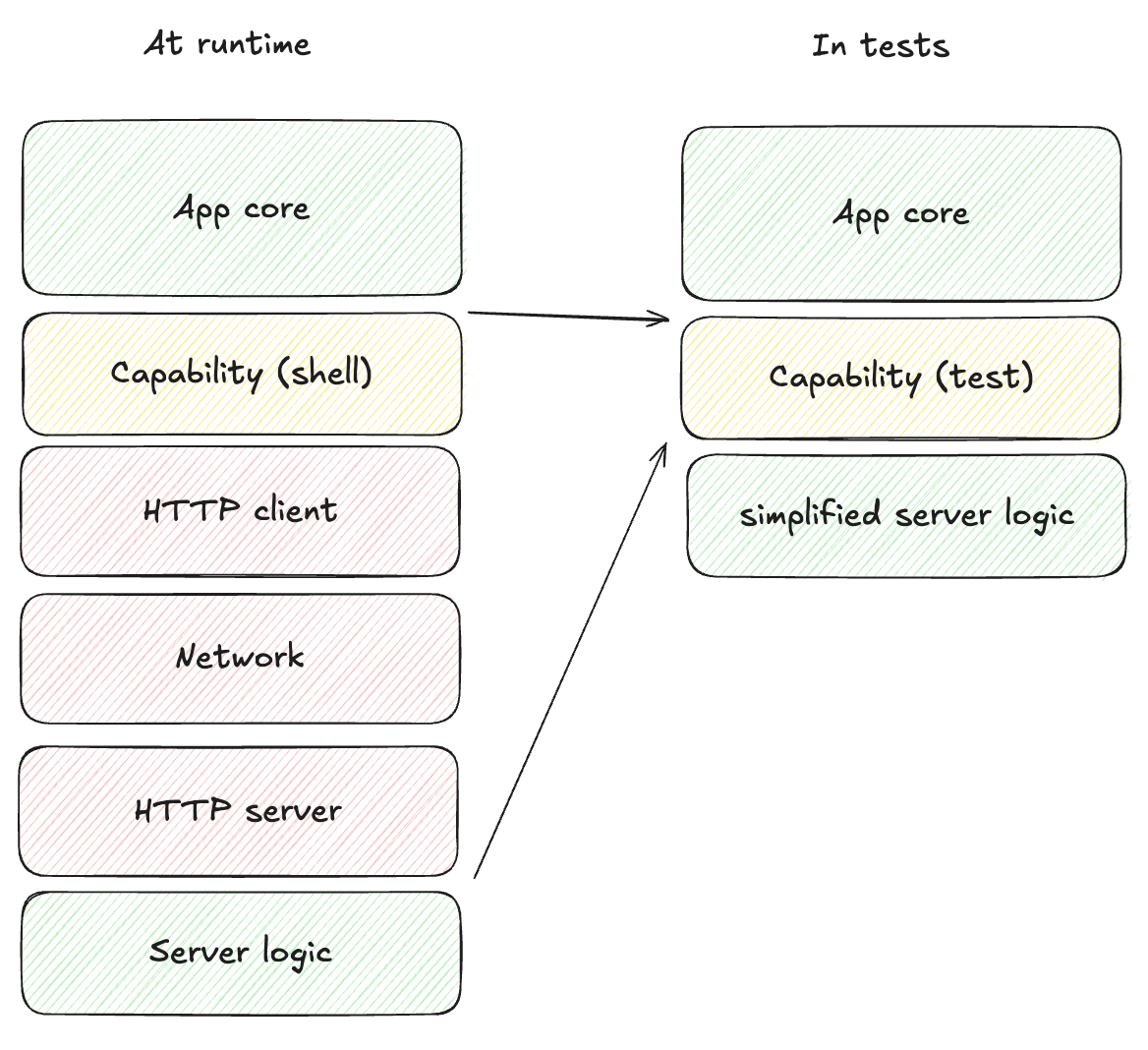
With that, we can create an app instance and send it completely random (but deterministic) events, and make sure "nothing bad happens". The definition of what that means is specific to each app, but just to illustrate some options:
- Introduce randomised errors to your fake API and see they are handled correctly
- Randomly lose data in storage and make sure the app recovers
- Make sure timeouts work correctly by randomly firing them first
- Check that any other invariants hold, e.g. anything time-related only moves forward (counters count up), storage remains referentially consistent, logically impossible states do not happen (ideally they would be impossible to represent, but sometimes that's too hard)
When we do that, we can then run this pseudo random process, for hours if we like, and let it find any bugs for us. To reproduce them, all we need is the random seed used for the specific test run.
In practice, Crux apps will mostly be able to run at thousands of events a second, and these tests will explore more of the state space than we ever could with manual unit tests.
This type of testing is usually reserved to consensus algorithms and network protocols (where anything that can happen will happen and they have to be rock solid), because setting up the test harness is just too much work. But with managed effects it is a few hundred lines of additional code. For a modestly sized app, a testing harness like that will only take a few days to write. We may even ship building blocks of such test harness with Crux in the future.